给大家介绍一个简单的翻墙的方法
现状
由于为了网络安全,大量提供VPN服务的公司被关掉,以前那种虽然网速不快的付费翻墙服务也没法用了。以前同事还在自己的服务器上搭建了一个VPN服务,但是接连收到阿里云的消息,吓得赶紧关掉。顶多使用一些镜像Google来查询问题,但是也会出现不能用的时候,十分不方便。
解决方案
条件:一台服务器 + xshell + chrome + SwitchySharp扩展程序。
1 首先使用xshell通过ssh连接到远程服务器上。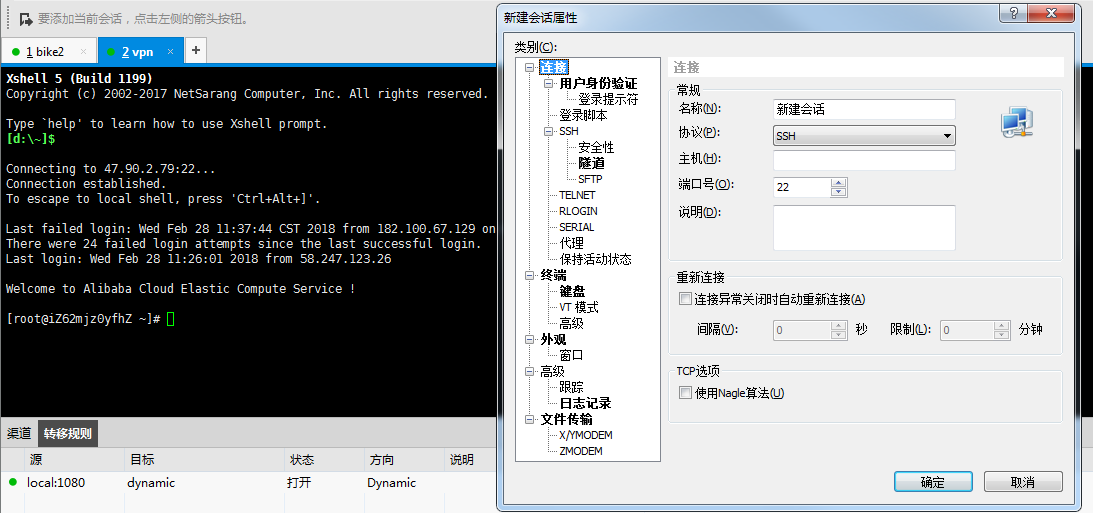
2连接成功之后打开隧道窗格显示(查看-> 隧道窗格),此时xshell底部会出现如下窗格
3 选中转移规则,在下面的空白处右键添加,类型选择Dynamic(SOCKS4/5),侦听端口自定义,默认1080。创建成功之后底部就会显示。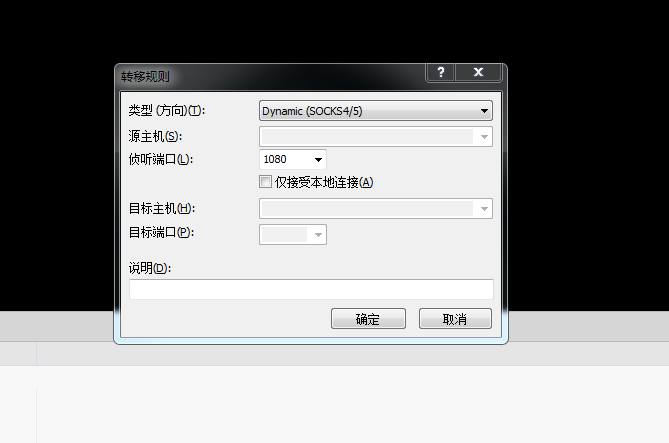
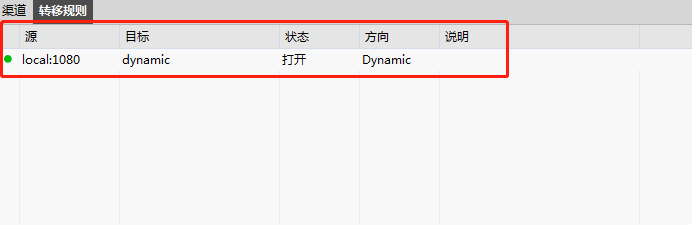
这样xshell中配置完成,相当只要本机把数据发生到刚才指定的端口,数据就会传输到我们的远程服务器上。
4在Chrome中添加SwitchySharp插件。
5在SwitchySharp中添加一个情景模式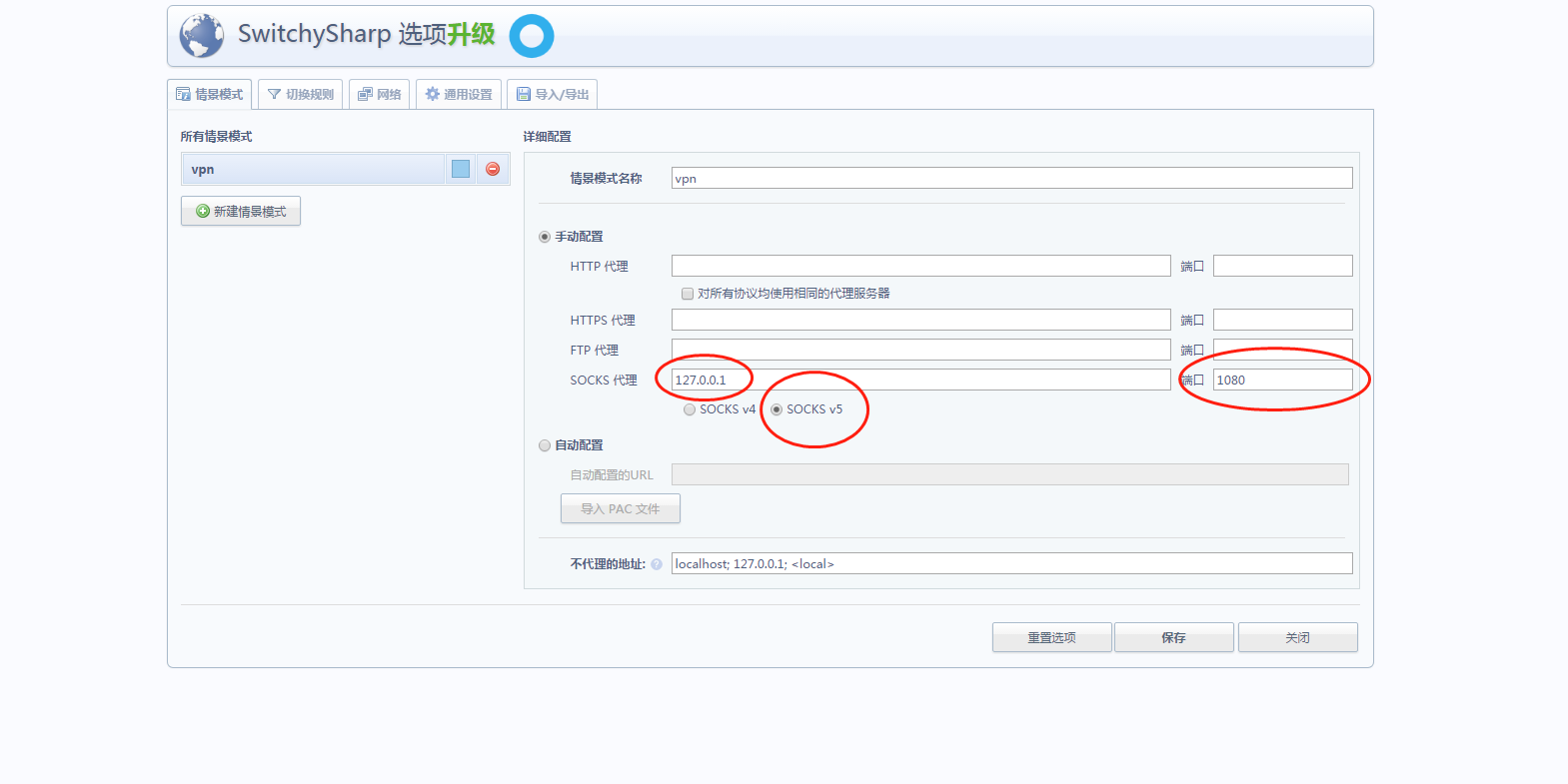
6大功告成。每次想要爬梯子的时候只要打开xshell连接到远程服务器(保证隧道连接建立),然后再SwitchySharp选中对应模式即可。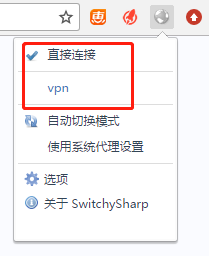
最后
希望大家好好利用工具,为社会主义建设作出贡献!